The code for this part is available in this commit.
We've fixed most of the notorious problems with 3D rendering and perspective interpolation, but there's still one problem left. We can draw a cube, but what if we disable back-face culling?
That's clearly not great.
Contents
Rendering order matters
Well, if disabling back-face culling breaks our cube, then...don't disable it? Of course, it's not that simple. It only works because a cube is a convex object. We can easily make a non-convex scene by rendering two cubes: first, one closer to the camera, and then one further from it (in this exact order!). Then, the further cube will be drawn on top of the closer one, even with back-face culling enabled:
Back-face culling can remove invisible faces from a single convex object, but between two separate cubes nothing tells our rendering engine about what should be drawn on top of what.
One of the solutions that comes up to mind is sorting everything in relation to the camera, which is called the painter's algorithm. It's called like that because that's how painters do things: draw far away objects (e.g. mountains) first, draw closer objects (e.g. a forest) next, draw even closer objects on top of them (e.g. a house), etc. This might work in painting, but it doesn't work in computer graphics. First, there are cases when no ordering on the input triangles can produce a solution:
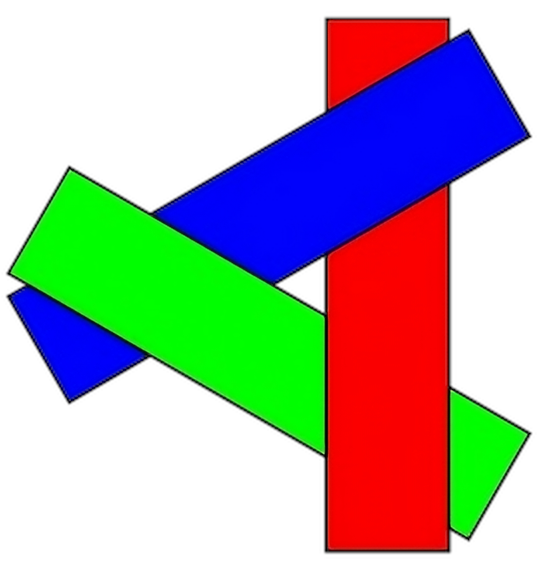
Secondly, it's not clear what we should do when rendering intersecting triangles. In both these cases we'd probably have to tessellate the input triangles into finer triangles, and figuring out how exactly to do this can be tricky.
Also, sorting is a costly operation, and we need to do it on all triangles in the scene, which completely breaks our API of independent decoupled draw calls.
Depth buffer
Of course, there is another solution. It comes with it's own downsides, but these turn out to be more manageable. This solution is called the depth buffer.
Here's the idea: when outputting a pixel color, let's also write it's distance to the camera somewhere. Say, we'd have a full-screen sized buffer with such distances, one number per each pixel. Then, when drawing a pixel, we simply write this pixel's camera distance to that buffer. Then, if we draw something else, we compare the distance of our new pixel with what is already remembered in the depth buffer: if the depth buffer value is smaller, it means there's something on screen already that is closer to the camera than our current pixel, and we skip outputting the current pixel, because it is occluded. This distance comparison thing is called the depth test.
The actual value written to the depth buffer is the post-projection \(\frac{Z}{W}\), mapped from the \([-1, 1]\) range to whatever the depth buffer format supports. Recall that we've carefully crafted our perspective projection matrix so that the range \([\text{near},\text{far}]\) of Z coordinates maps precisely to \([-1, 1]\) after perspective divide.
Typically, depth buffers are unsigned normalized 24-bit buffers, meaning that each depth buffer value is represented by a number \([0..16777215]\). However, C++ (and most other languages too) doesn't have a built-in 24-bit unsigned integer type, so I'll use 32-bit unsigned ints instead. This won't change much other than a few constants in the code. You can use a 16-bit buffer instead, which is also a common value supported by GPUs.
So, to use a depth buffer, we need to allocate its memory first. We already have an image_view type that references an image, but this time we need to own the image itself, so we'll create an image class. I'm making it a template, since we'll need images with different pixel types when we start working on textures. Let's create a new file:
#pragma once
#include <rasterizer/image_view.hpp>
#include <cstdint>
#include <memory>
namespace rasterizer
{
template <typename Pixel>
struct image
{
std::unique_ptr<Pixel[]> pixels;
std::uint32_t width = 0;
std::uint32_t height = 0;
explicit operator bool() const
{
return pixels != nullptr;
}
};
}We're just storing an array of pixels in a std::unique_ptr<Pixel[]>, and we have an operator to check if the image is valid (i.e. has been allocated).
Now, to actually allocate the image, let's add a static method to this class:
static image allocate(std::uint32_t width, std::uint32_t height)
{
return image
{
.pixels = std::make_unique<Pixel[]>(width * height),
.width = width,
.height = height,
};
}i.e. we simply allocate an array of pixels. Finally, we'll want to convert this image into an image_view, so we add a (non-static) method for that:
image_view<Pixel> view()
{
return image_view<Pixel>
{
.pixels = pixels.get(),
.width = width,
.height = height,
};
}Oh, and, for that we need to make image_view a template as well:
template <typename Pixel>
struct image_view
{
Pixel * pixels = nullptr;
std::uint32_t width = 0;
std::uint32_t height = 0;
explicit operator bool() const
{
return pixels != nullptr;
}
Pixel & at(std::uint32_t x, std::uint32_t y) const
{
return pixels[x + y * width];
}
};Framebuffer
Now that we need to render both a color buffer and a depth buffer, it's a good idea to bundle these together. The object containing various output buffers for rendering is typically called a framebuffer. Let's create a separate file for it as well:
#pragma once
#include <rasterizer/image_view.hpp>
#include <rasterizer/color.hpp>
namespace rasterizer
{
struct framebuffer
{
image_view<color4ub> color;
image_view<std::uint32_t> depth;
std::uint32_t width() const
{
if (color)
return color.width;
return depth.width;
}
std::uint32_t height() const
{
if (color)
return color.height;
return depth.height;
}
};
}This struct simply stores two image views: one for the color buffer, one for the depth buffer. Note that I've hard-coded the depth buffer format to be uint32_t.
I've also added two convenience methods to retrieve the framebuffer width and height: they return the size of the color buffer if it is present, otherwise they fallback to the size of the depth buffer. Note that I'm assuming that the size of the color buffer and depth buffer is the same; otherwise, it is an error and can probably crash. We could add a valid() method to check that, and refuse to render to an invalid framebuffer.
Why can a color buffer be missing? Isn't that the actual rendering result, after all? Well, wait until we implement shadow mapping :)
Now we need to tweak our draw function: now it takes a full framebuffer instead of just a color_buffer:
void draw(framebuffer const & framebuffer, viewport const & viewport,
draw_command const & command);Now, in the rasterization code, we need to change color_buffer.width to framebuffer.width() and similarly for height, and we also need to check if the color buffer is present when outputting the color:
if (framebuffer.color)
framebuffer.color.at(x, y) =
to_color4ub(l0 * v0.color + l1 * v1.color + l2 * v2.color);Great! Now let's fix our main rendering loop to work with the new framebuffer abstraction:
framebuffer framebuffer
{
.color = {
.pixels = (color4ub *)draw_surface->pixels,
.width = (std::uint32_t)width,
.height = (std::uint32_t)height,
},
};
...
clear(framebuffer.color, {0.9f, 0.9f, 0.9f, 1.f});
...
draw(framebuffer, viewport,
draw_command { ... }
);We still don't have the depth buffer, though. Let's define an image for it somewhere before the main loop:
...
image<std::uint32_t> depth_buffer;
...Then, when the window is resized, we reset this image (so that we know we have to reallocate it):
case SDL_WINDOWEVENT_RESIZED:
...
depth_buffer = {};
break;
Then, in the beginning of a new frame, allocate the depth buffer if needed:
if (!depth_buffer)
depth_buffer = image<std::uint32_t>::allocate(width, height);
And finally add the depth buffer to our framebuffer setup:
framebuffer framebuffer
{
.color = {
.pixels = (color4ub *)draw_surface->pixels,
.width = (std::uint32_t)width,
.height = (std::uint32_t)height,
},
.depth = depth_buffer.view(),
};Nice, we have a depth buffer! It isn't used by the rasterization code, though. Time to fix that.
Depth test
The usual way to use the depth buffer is called LESS: if the depth value (i.e. \(\frac{Z}{W}\)) of the current pixel is less than what is written to the depth buffer, the pixel is said to pass the depth test, in which case it proceeds to be drawn on screen. However, other modes can be useful as well (for Z-prepass, reversed-Z, and other things). So, let's create a new enum for this depth testing mode, pretty much copying what various graphics APIs support:
enum class depth_test_mode
{
never,
always,
less,
less_equal,
greater,
greater_equal,
equal,
not_equal,
};Now, occasionally it is useful to perform the depth test, but skip writing the depth value of the current pixel to the depth buffer. This can be used for transparent objects, particle systems, that sort of thing.
So, let's make a struct holding all settings related to the depth test:
struct depth_settings
{
bool write = true;
depth_test_mode mode = depth_test_mode::always;
};By default, depth write is enabled, and the depth test mode is set to ALWAYS, meaning that all pixels will pass the test. This is a nice and safe default that will make code that doesn't need depth test work with no changes required.
Now add this struct to our draw_command:
struct draw_command
{
struct mesh mesh;
enum cull_mode cull_mode = cull_mode::none;
depth_settings depth = {};
matrix4x4f transform = matrix4x4f::identity();
};To actually support depth test in our rasterizer, let's first implement a convenience function that deals with all the various depth test modes (I've put it in our anonymous namespace in renderer.cpp):
bool depth_test_passed(depth_test_mode mode,
std::uint32_t value, std::uint32_t reference)
{
switch (mode)
{
case depth_test_mode::always: return true;
case depth_test_mode::never: return false;
case depth_test_mode::less: return value < reference;
case depth_test_mode::less_equal: return value <= reference;
case depth_test_mode::greater: return value > reference;
case depth_test_mode::greater_equal: return value >= reference;
case depth_test_mode::equal: return value == reference;
case depth_test_mode::not_equal: return value != reference;
}
// Unreachable
return true;
}Now, when rasterizing a pixel, before outputting the final color, check if a depth buffer is present. If it is, compute the intepolated Z-value (which will automatically work correctly, thanks to perspective-correct interpolation we've added earlier), and perform the depth test. If it doesn't pass, skip the current pixel altogether:
if (framebuffer.depth)
{
float z = l0 * v0.position.z + l1 * v1.position.z + l2 * v2.position.z;
// Convert from [-1, 1] to [0, UINT32_MAX]
std::uint32_t depth = (0.5f + 0.5f * z) * std::uint32_t(-1);
auto & old_depth = framebuffer.depth.at(x, y);
if (!depth_test_passed(command.depth.mode, depth, old_depth))
continue;
if (command.depth.write)
old_depth = depth;
}uint32_t(-1) is just a lazy way of getting the maximal possible value of uint32_t.
If we try to use this new depth test in our rendering, it won't work! Most probably you'll see nothing on the screen.
Clearing the depth buffer
We've forgot one crucial thing: clearing the depth buffer. Right now, each frame we use the depth buffer generated on the previous frame. Effectively, the depth buffer contains the smallest depth value (using depth_test_mode::less) that ever occurred in a particular pixel during the whole run of the program. Typical pixel depth values are larger than the smallest one possible in a particular scene, so they almost never pass the depth test.
The fix is easy: just add a function that clears a depth buffer with some fixed uint32_t value
void clear(image_view<std::uint32_t> const & depth_buffer,
std::uint32_t value)
{
auto ptr = depth_buffer.pixels;
auto size = depth_buffer.width * depth_buffer.height;
std::fill(ptr, ptr + size, value);
}And call this function right after clearing the main color buffer:
clear(framebuffer.color, {0.9f, 0.9f, 0.9f, 1.f});
clear(framebuffer.depth, -1);Now, set up a scene with our usual cube, disable back-face culling, and turn on the depth test (and add some projection matrix, and a model matrix to rotate the cube):
draw(framebuffer, viewport,
draw_command{
.mesh = cube,
.depth = {
.mode = depth_test_mode::less,
},
.transform = projection * view * model,
}
);Btw, we've disabled culling just for a test, to see depth test in action. In actual code, we should keep culling on, because it lets us rasterize 2x less triangles.
We should see our glorious cube now with no artifacts:
If we add another cube further from camera, the image shouldn't change, because the further cube will be occluded.
To really stress-test our depth test, create five intersecting rotating cubes, e.g. by offsetting them a little bit in the X direction:
for (int i = -2; i <= 2; ++i)
draw(framebuffer, viewport,
draw_command{
.mesh = cube,
.cull_mode = cull_mode::cw,
.depth = {
.mode = depth_test_mode::less,
},
.transform = projection
* view
* matrix4x4f::translate({i, 0.f, 0.f})
* model,
}
);Here, my model matrix rotates the cube, view matrix moves them away from camera in -Z direction, and projection matrix implements the perspective projection.
We should see something like this:
Notice how the cubes seem to perfectly occlude each other whenever they intersect. We're now fully 3D! Congrats.
| \(\leftarrow\) Part 5: Fixing issues with 3D | Source code for this part | Part 7: Shedding some light (wip) \(\rightarrow\) |